
Latest News
Introduction
Welcome to Forward Learning from Experience (FLEX), a novel learning paradigm that shifts learning from modifying model parameters to constructing and leveraging an evolvable experience library.
By continuously expanding and refining this library, agents can progressively acquire deeper insights and knowledge, enhancing their cognitive capabilities with accumulated experiences.
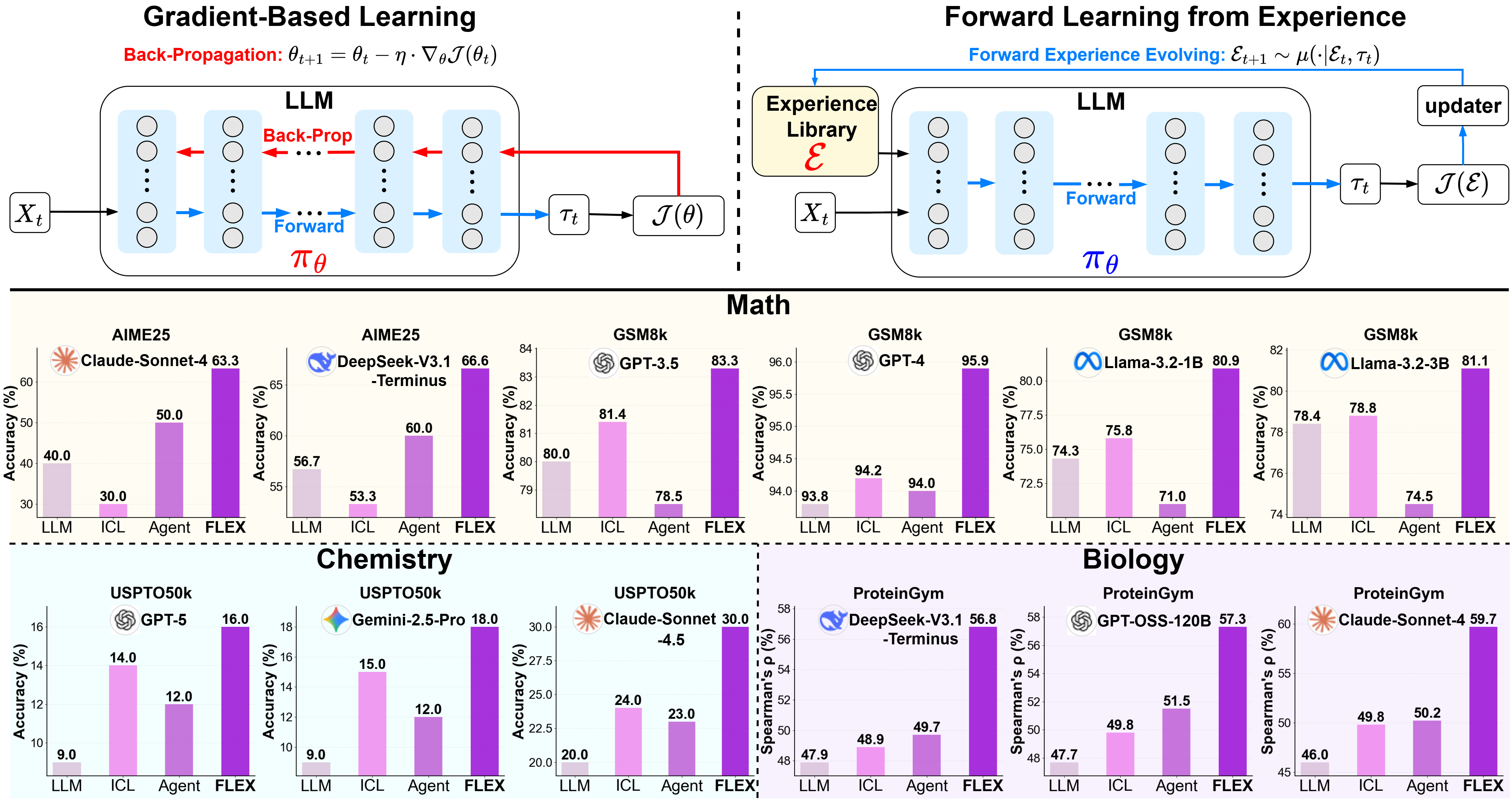
Overview of the FLEX paradigm showing the interaction between agents and the experience library
🎯 Experimental Results
We conduct extensive experiments across diverse challenging scientific domains:
- AIME25 (Olympiad-level mathematics): Improvement from 40% to 63.3%
- USPTO50k (Chemical retrosynthesis): Improvement from 20% to 30%
- ProteinGym (Protein fitness prediction): Improvement from 46% to 60%
Key Contributions
We propose FLEX, a new learning paradigm for the agentic era. It redefines learning as a forward exploration and experience distillation process, enabling LLM agents to evolve dynamically without gradient-based tuning.
We provide a comprehensive framework for FLEX, including a unified mathematical formulation with theoretical justifications, a practical instantiation with concrete mechanisms, and an empirical demonstration of its effectiveness on diverse scientific benchmarks.
We discover and empirically validate a scaling law for the experience library, showing that agent performance scales predictably with accumulated knowledge and revealing a path towards a collaborative experience ecosystem.
We introduce and demonstrate the principle of intelligence inheritance, where distilled experience can be transferred between agents in a plug-and-play manner, enabling instant knowledge assimilation and bypassing redundant learning.
Methodology
FLEX introduces a fundamentally different approach to machine learning by focusing on experience accumulation rather than parameter optimization.

Comparison between gradient-based learning and FLEX, highlighting the interaction among
the actor π, updater μ, and experience library ℰ
The system comprises three main components:
π(Actor): Executes tasks using available experienceμ(Updater): Refines and expands the experience libraryℰ(Experience Library): Stores and organizes learned knowledge
Main Results
FLEX achieves consistent and significant improvements across diverse scientific domains, demonstrating its effectiveness as a universal learning paradigm.
| Benchmark | Models | LLM | ICL | ReAct | FLEX |
|---|---|---|---|---|---|
| Math | |||||
| AIME25 | Claude-Sonnet-4 | 40.0 | 30.0 (-10.0) | 50.0 (+10.0) | 63.3 (+23.3) |
| DeepSeek-V3.1-Terminus | 56.7 | 53.3 (-3.3) | 60.0 (+3.3) | 66.6 (+10.0) | |
| GSM8k | GPT-3.5 | 80.8 | 81.4 (+0.6) | 78.5 (-2.3) | 83.3 (+3.3) |
| GPT-4 | 93.8 | 94.2 (+0.4) | 94.0 (+0.2) | 95.9 (+2.1) | |
| Llama-3.2-1B | 74.3 | 75.8 (+1.5) | 71.0 (-3.3) | 80.9 (+6.6) | |
| Llama-3.2-3B | 78.4 | 78.8 (+0.4) | 74.5 (-3.9) | 81.1 (+2.7) | |
| Chemistry | |||||
| USPTO50k | GPT-5 | 9.0 | 14.0 (+5.0) | 12.0 (+3.0) | 16.0 (+7.0) |
| Gemini-2.5-Pro | 9.0 | 15.0 (+6.0) | 12.0 (+3.0) | 18.0 (+9.0) | |
| Claude-Sonnet-4.5 | 20.0 | 24.0 (+4.0) | 23.0 (+3.0) | 30.0 (+10.0) | |
| Biology | |||||
| ProteinGym | DeepSeek-V3.1-Terminus | 47.9 | 48.9 (+1.0) | 48.6 (+0.7) | 56.8 (+8.9) |
| GPT-OSS-120B | 47.7 | 49.8 (+2.1) | 51.5 (+3.8) | 57.3 (+9.6) | |
| Claude-Sonnet-4 | 46.0 | 49.8 (+3.8) | 50.2 (+4.2) | 59.7 (+13.7) | |
💡 Key Takeaways
- ✓ Universal Effectiveness: FLEX consistently improves performance across mathematics, chemistry, and biology
- ✓ Model Agnostic: Benefits small models (Llama-3.2-1B) and large models (GPT-4, Claude) alike
- ✓ Practical Impact: Up to 100% relative improvement on challenging benchmarks
The Scaling Law of Experience
FLEX demonstrates predictable scaling behavior: agent performance improves systematically as the experience library grows, revealing three distinct scaling regimes.
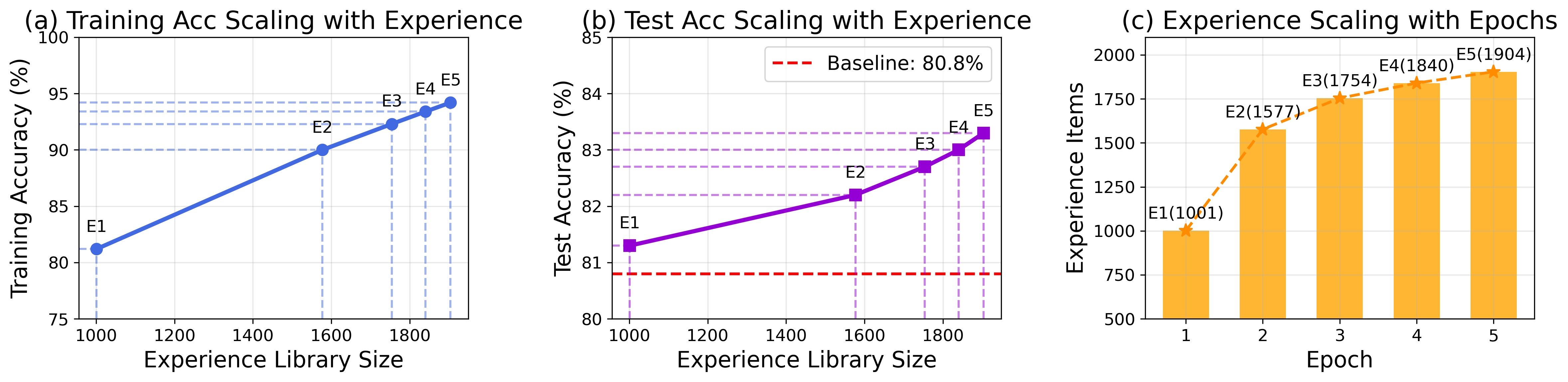
Training dynamics on GSM8K across 5 epochs showing how performance scales with experience library size
1,001 → 1,904 items
Stable predictions
Intelligent coverage
💡 A New Scaling Paradigm
Beyond traditional scaling (parameters, compute), FLEX introduces scaling with experience — a principled framework for continuous improvement through knowledge accumulation, offering predictable performance gains without parameter updates.
Inheritance of the Experience Library
The experience library is portable and reusable — it can be seamlessly transferred across different agents, enabling two powerful effects that transcend traditional model boundaries.
📊 View Detailed Transfer Results
| AIME25 | ||||
|---|---|---|---|---|
| Model | ReAct | + Claude | + DeepSeek | |
| Claude-Sonnet-4 | 50.0 | 63.3 (+13.3) | 66.7 (+16.7) | |
| DeepSeek-V3.1-Terminus | 60.0 | 66.7 (+6.7) | 66.7 (+6.7) | |
| USPTO50k | ||||
|---|---|---|---|---|
| Model | ReAct | + GPT | + Gemini | + Claude |
| GPT-5 | 12.0 | 16.0 (+4.0) | 18.0 (+6.0) | 15.0 (+3.0) |
| Gemini-2.5-Pro | 12.0 | 14.0 (+2.0) | 18.0 (+6.0) | 23.0 (+11.0) |
| Claude-Sonnet-4.5 | 23.0 | 28.0 (+5.0) | 30.0 (+7.0) | 30.0 (+7.0) |
| ProteinGym | |||
|---|---|---|---|
| Model | ReAct | + Qwen | + DeepSeek |
| GPT-OSS | 51.5 | 55.0 (+3.5) | 56.6 (+5.1) |
🌐 Towards Universal Experience Libraries
These inheritance properties open a path to creating universal experience libraries — single, reusable knowledge modules that can enhance entire AI ecosystems without individual training, enabling a collaborative intelligence paradigm.
Case Study
Explore how FLEX's experience library corrects critical failures across three scientific domains by injecting domain-specific knowledge and procedural guidance.
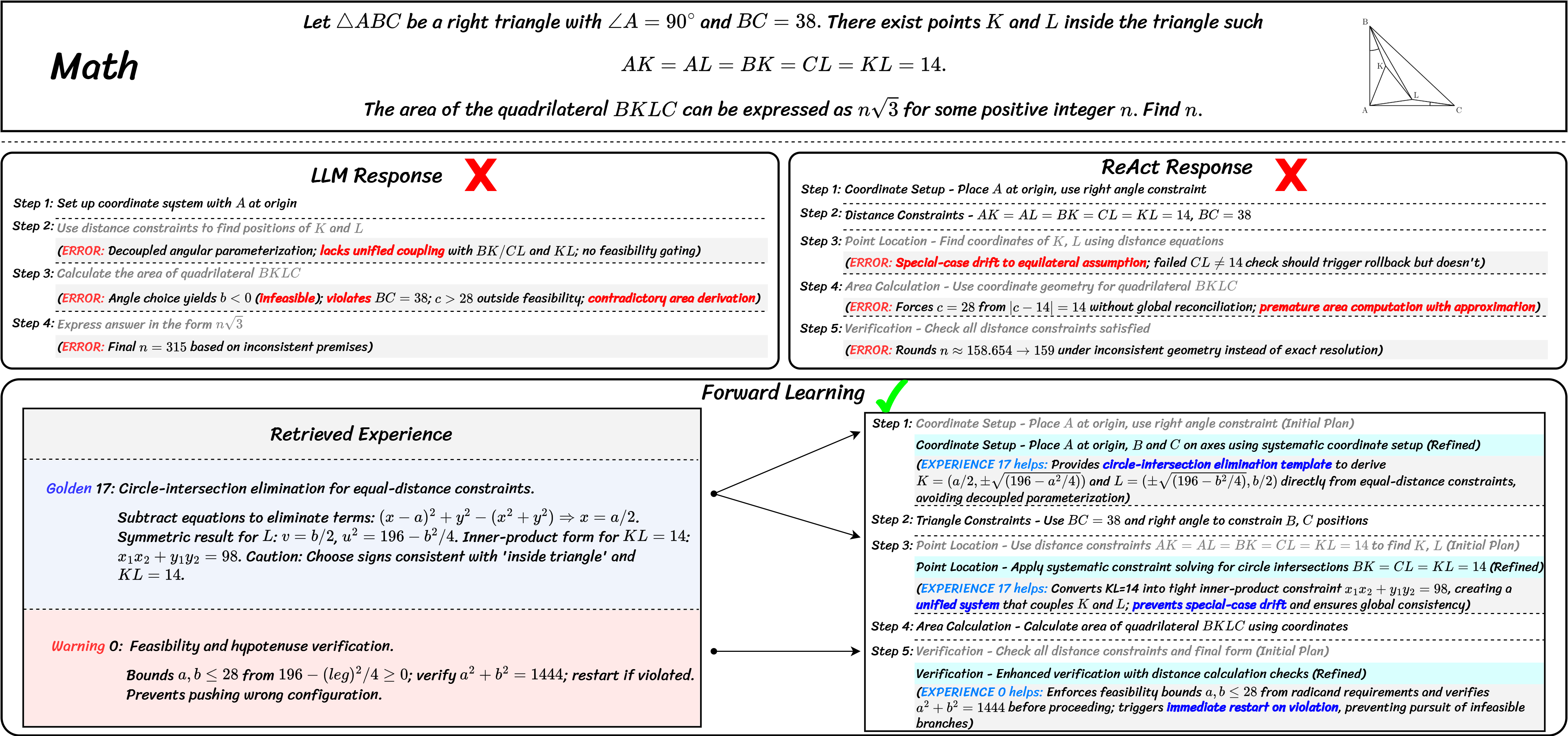
🔢 Mathematics: Geometric Constraint Reasoning
The problem-solving trajectories reveal fundamental reasoning gaps in baseline approaches. The naive LLM fails by decoupling geometric constraints, leading to infeasible side lengths. The ReAct agent, while more structured, drifts into special-case assumptions without verifying global consistency.
FLEX transforms this process by injecting structured procedural knowledge. By retrieving a reusable algebraic template and critical feasibility checks, it directly addresses core LLM limitations of logical drift and constraint violation. The distilled experience transforms the agent's process from heuristic-driven exploration into a deterministic solve-verify loop, enabling systematic discovery of correct parameters.
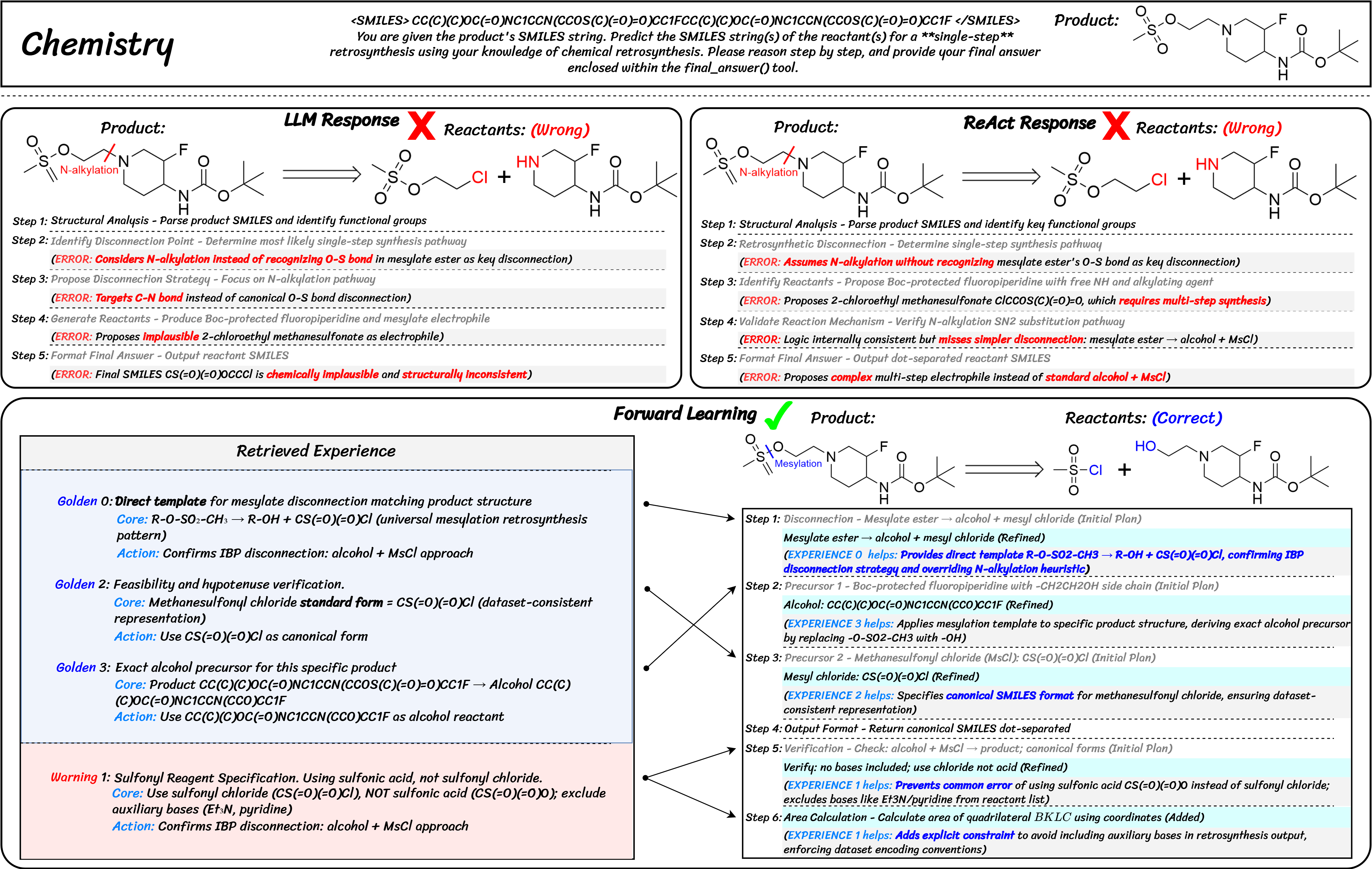
⚗️ Chemistry: Retrosynthesis Disconnection Strategy
The trajectories expose a critical gap in domain-specific reasoning. Both naive LLM and vanilla ReAct make the same fundamental error: despite correctly identifying the mesylate group, they misidentify the disconnection point by prioritizing a plausible but incorrect N-alkylation pathway.
FLEX succeeds by leveraging its experience library to bridge this knowledge gap. It retrieves an explicit template that overrides the flawed heuristic and enforces the canonical O-S bond disconnection. The experience library functions as an external knowledge substrate, injecting proven procedural scaffolds and domain-specific constraints into the agent's workflow.
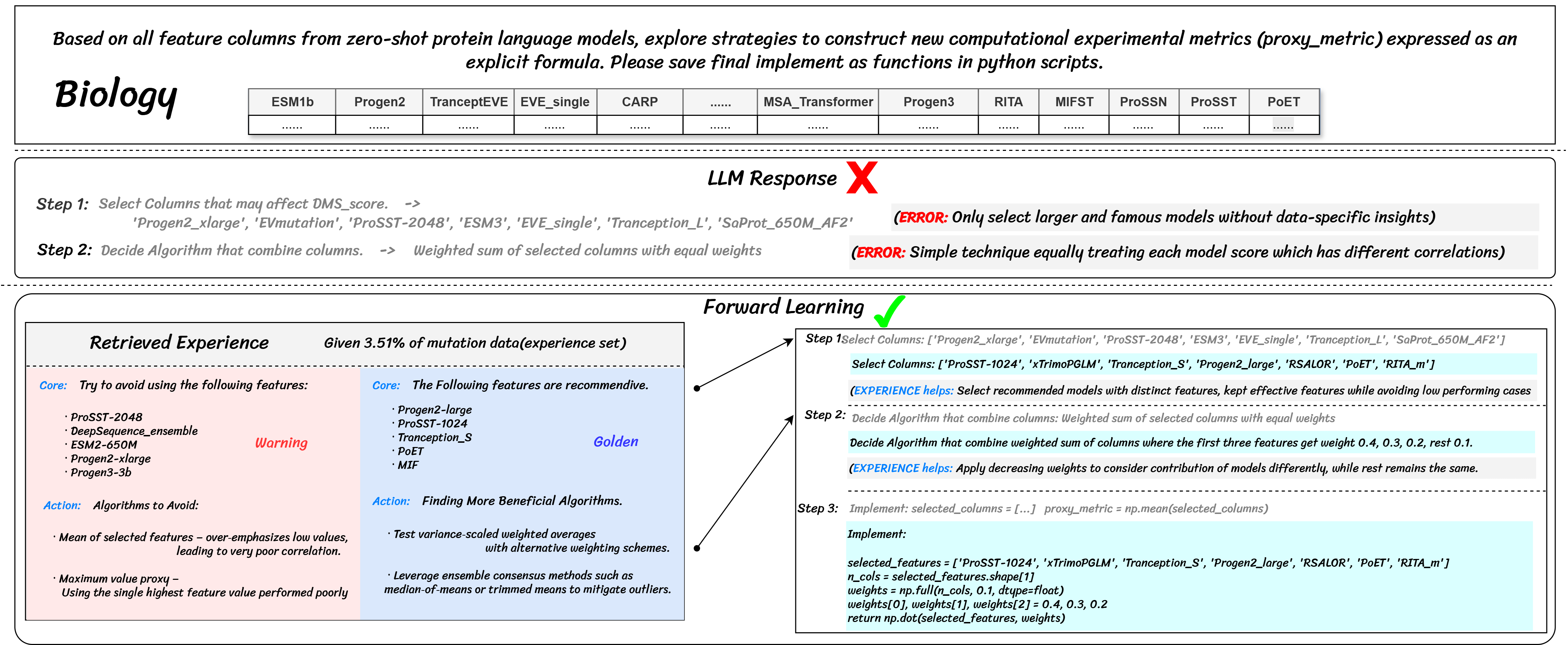
🧬 Biology: Protein Fitness Landscape Navigation
This case demonstrates how agents learn from a deliberately designed experience library — golden rules, warnings, and core know-how. Unlike math and retrosynthesis, protein-fitness prediction rarely admits absolute right/wrong answers; instead, useful guidance must be distilled from empirical trial trajectories and cross-validation signals.
The library captures those trajectories as reusable micro-strategies and failure patterns, enabling the agent to adapt a generic regression objective to the idiosyncrasies of specific proteins. By overlaying proven procedural scaffolds onto the frozen LLM's reasoning, the experience library encourages more valuable and diverse explorations of the fitness landscape.
Discussion
The aspiration to create intelligent agents that evolve through lived experience is a long-standing and central theme in artificial intelligence. This discussion connects our research to this enduring quest, reflecting on potential futures and historical context. We frame our contributions not as conclusions, but as a humble step in an ongoing, collective journey.
🔄 Toward Continuous Learning
A central goal in AI is to enable agents to learn continuously from their interactions, much like living organisms do. This pursuit hints at a future where AI systems are not static artifacts, but dynamic partners capable of adapting in real time.
For years, the research community has explored various avenues toward this goal, often seeking learning paradigms that are more "forward-looking" than traditional back-propagation. However, most approaches have been constrained to numerical optimization tasks.
The semantic capabilities of modern LLMs offer a new lens for this quest. It becomes possible to explore learning not only as a numerical optimization task but as a process of reasoned reflection. Our explorations suggest this is a worthwhile direction, raising the possibility for a new generation of AI systems whose learning processes are inherently more auditable and aligned with a lifelong learning model.
🌐 Heading to a Collective Wisdom
Beyond individual capability, another grand challenge is fostering a form of collective intelligence, mirroring how human progress is built upon shared knowledge. One can envision a future where a global network of specialized agents collaborate, forming a collective scientific mind to accelerate progress on humanity's greatest challenges.
A key historical obstacle to this vision has been the absence of a robust medium to inherit wisdom across distinct AI agents. Traditional approaches embedded knowledge within model parameters, making transfer and collaboration difficult.
The concept of decoupling learned experience from an agent's internal parameters represents a hopeful path forward. Our explorations suggest that distilled experience can indeed serve as a viable medium for inheritance, adding a small contribution to the larger effort of building a foundation upon which a more synergistic AI ecosystem might one day be built.
🔍 Learning in a Transparent Way
Integral to the future of AI is the development of systems whose reasoning is transparent. This points toward a future where human-AI collaboration is built on a foundation of shared understanding, which is crucial for their integration into critical societal functions.
The "black box" nature of many deep learning models has presented a persistent barrier to this goal. Understanding why a model makes certain decisions has remained a fundamental challenge in the field.
An experience-driven learning paradigm inherently addresses this challenge. When an agent's growth is chronicled as a series of explicit, human-readable experiences, its evolution becomes an open book. This transparency provides a direct mechanism for meaningful human-in-the-loop interaction, allowing experts to understand, guide, and even enrich an agent's learning journey. It represents a step toward a more white-box model of AI development, where the process of learning is as important as the final performance.
In conclusion, the ideas explored here are offered as a contribution to an ongoing conversation. It is our sincere hope that this work serves as one humble effort for the field, contributing to a future where AI evolves as a more dynamic, collaborative, and transparent partner in the human endeavor.
🌳 FLEX Research Series
FLEX is the foundational work of an evolving research series. As we explore new applications, methodologies, and theoretical insights, this section will grow to showcase the expanding ecosystem of FLEX-based research across diverse domains.
Loading series works...
Core Research Team
Join the FLEX Community
Explore the future of AI learning through experience accumulation
Citation
If you use FLEX in your research, please cite our paper:
@misc{cai2025flexcontinuousagentevolution,
title={FLEX: Continuous Agent Evolution via Forward Learning from Experience},
author={Zhicheng Cai and Xinyuan Guo and Yu Pei and JiangTao Feng and Jiangjie Chen and Ya-Qin Zhang and Wei-Ying Ma and Mingxuan Wang and Hao Zhou},
year={2025},
eprint={2511.06449},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2511.06449},
}